Practical Guide to Create a Two-Layered Recommendation System
 Medium.com
Medium.com
A developer’s perspective (MLOps inside)
At iFunny, we are trying to compose the best possible feed of memes and funny videos. To rate our job, people use smile/dislike buttons and comments. Some of them even post memes about our efforts.
The idea of why we need multiple layers in RecSys is already described here. This article will look at how to deploy such a system and talk about a high-level architectural overview of the recommendation services at FUNCORP.
First of all, let’s define what we want to achieve.
Useful definitions
-
Online feature — a feature, the value of which must be updated as soon as possible, but no later than one minute.
-
Offline feature — a feature, the value of which might be updated once per hour/day/week.
-
Feature group — the list of features in the specified order.
-
Model features — are the list of feature groups used to construct the input tensor for the model.
-
A/B shuffle — generation of A/B tests, used for shuffling users to the new groups if an experiment significantly impacted vital metrics.
Requirements
The system must:
-
Support multiple projects.
-
Support multiple ongoing A/B tests meaning that — models might be trained on the subset of the data selected by users of the A/B group; datasets might be prepared concerning users’ A/B group and current shuffle.
-
Support up to 50 deployed models, with the maximum size of a single model in memory up to 5GB.
-
Support different models, such as rank models and candidate selection models.
-
Be able to update models as frequently as once an hour. “Update model” in this context means to deploy a retrained version of the same model.
-
Support both online and offline features for inference and training.
-
Reduce resource utilization at least in half. I must note here that our old solution consisted of 25 instances of quite pricey AWS servers running 24/7.
Now let’s design a system that is going to satisfy our requirements
Theoretically, we would need five components:
-
Service with an HTTP API will provide inference models (inference service).
-
Service to schedule data preparations, training, and model deployments.
-
Database or another repository to store features for training and inference.
-
Service to run feature computations (Spark, Kafka Streams, Flink, etc.).
-
External data sources: Kafka with actions, Database with user/content data.
We would need two databases for different workloads and a cache for inference service.

Data sources
There is not much to say about data sources. I will just give an approximation of the data amount we are dealing with:
-
12B+ events in Kafka are being read both online and in batches.
-
Hundreds of thousands of content entries monthly.
-
Tens of millions of monthly active users.
Inference service
The service is relatively straightforward but has some interesting details. For example, it is written in Kotlin as the rest of our backend. We decided to dump Python mainly because of developer productivity and worse tooling than Kotlin/Java. To make Kotlin work for ML model inference, we convert all models to ONNX format and premise them with ONNX runtime (Java). By doing this, we can:
-
Simplify deduction of any model to a single function call.
-
Avoid having multiple ML runtimes in the container.
Because ONNX allows us to be model-agnostic, we can replace or add a model in production with a single HTTP request.

As you might see, we have two different resources: “…/first-tier-model/” and “…/second-tier-model/.” They represent “layers” or “tiers” in the RecSys architecture. The resources have a lot of parameters that are caused by all types of things: the A/B-tests model is being used for test groups, projects, etc.
The downside of using ONNX is that we have to convert every model deployed to production, but the process is automated and takes only about 50 lines of Python code.
Inference service consists of three instances of the exact HTTP. How do we make sure they use the same model for every layer/experiment and other configuration options? We went with an event sourcing—like the approach here, the instance that receives a command to update the model, writes config in MongoDB, and then reads it from “change stream.” All the updates must be done via reading the change stream, not serving the HTTP.
Scheduler
We went with Airflow because it checks all the boxes:
-
Allows to schedule with different intervals, start times, timeouts, etc.
-
Allows backfills.
-
Supports streaming workloads (tasks that must work 24/7) deployment via “@once.”
-
Allows deploying pods to K8s.
-
Supports native spark + K8s integration.
We use all those features and start to write our provider with needed hooks, operators, and other goodies, for example, an operator to get current A/B-tests generation.
Another thing Airflow does for us is CD: once the model is trained, the Airflow task deploys the model to ML-inference via HTTP API.
“Feature store” (FS)
Instead of deploying or using existing feature stores, we went with just two databases to avoid the organizational load coming with FS. Our databases of choice are ClickHouse for storing historical data used in model training and analytics and MongoDB for online stores. Mongo was chosen because we have expertise in deploying and maintaining significant clusters of it. However, we use it basically as a key-value store, where a key is user/content ID and value is a feature group.
Both databases might store raw values instead of final feature values. For example, if the model needs smile rate (#smile/#views) database would contain both numbers of smiles and the number of views. This workaround was used to optimize DB load in streaming applications because without calculating the rate it is possible to write increments in DB without reading the latest value from it.
Features computation
We use Spark to do all kinds of data tasks. Here are just a few examples:
-
Structured streaming tasks to compute the “user actions” feature with 20s latency.
-
Batch tasks to prepare training data for NFM models.
-
Data validation tasks containing business logic, for example: “X Kafka topic can not be empty,” “Distribution of column Y in ClickHouse must match the distribution of field Z in Mongo.”
There is A LOT to talk about Spark, especially streaming, and our experience with doing everything in Kotlin. There will be another article about it. Stay tuned :).
Deployment
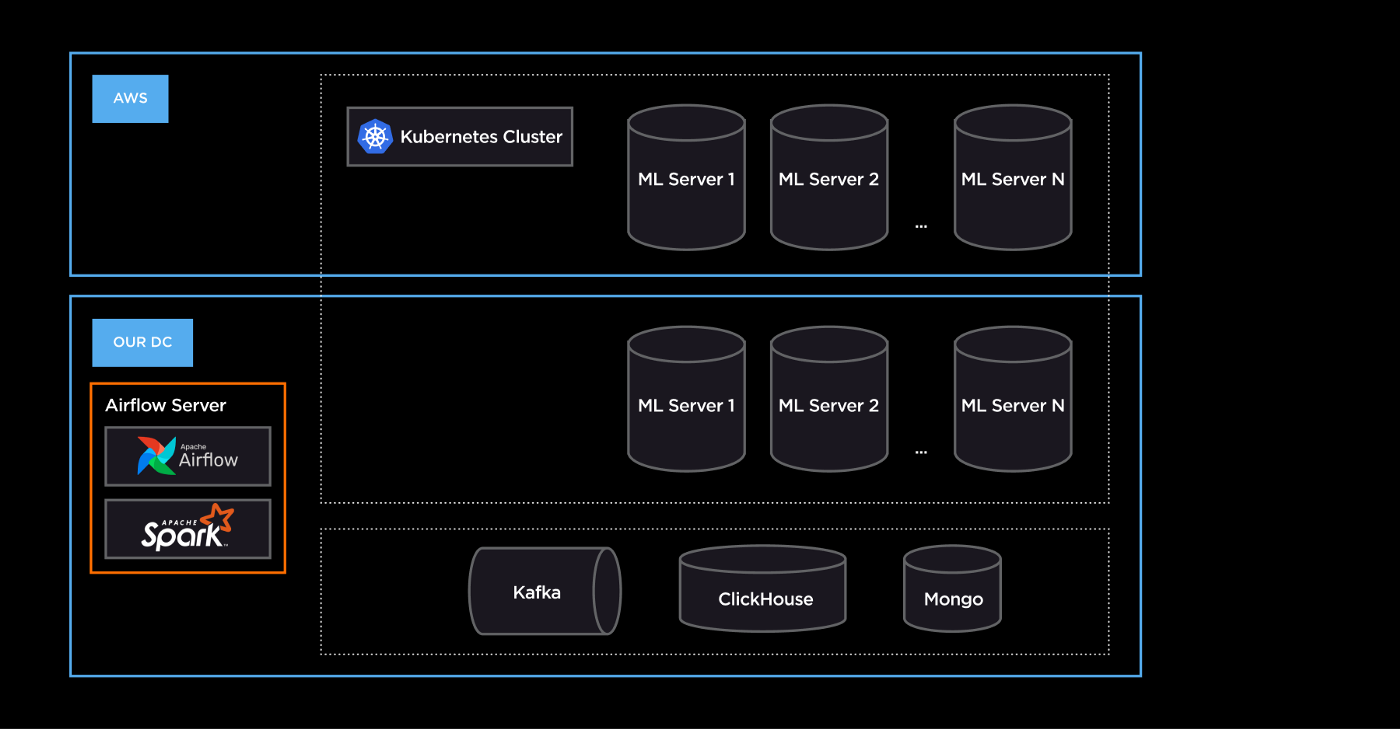
Оur Airflow instance is deployed as a standalone service alongside other services in our data center. The host with Airflow also contains Java and Spark 3.2.1 installation to be able to deploy Spark apps natively in K8s.
Our K8s clusters contain multiple nodes in our DC and various nodes in AWS, which allows us to optimize the costs while having an opportunity to extend resources if needed.
For now, our workload consists of KubernetesPodOperator and SparkSubmitOperator. Still, we are migrating to Airflow on K8s, which allows us to write Python code instead of wrapping it in a container and using KubernetesPodOperator.

Let’s add a simple online feature — “the number of user interactions” — to the system, e.g., likes and comments grouped by content type.
To calculate those features, we would use the stream of user events from Kafka and content type from MainMongo. Joining will be done by Mongo Spark connector, but I should note here that we could not use native join since it loads the whole collection from Mongo to the memory. Instead, we are making batch queries for the data collected in the span of Spark’s processingTime.
To deploy the application, we are going to write an Airflow DAG containing all the configurations for:
a) Online job.
b) Offline job.
c) Online import.
The DAGs consist of a single SparkSubmitOperator, which launches spark applications in the cluster mode inside the K8s cluster. After the initial import online job starts to work every five seconds and imports all the events to the online store while features are being read and cached by the ML service. The same Spark application with different run parameters writes features to the offline store used for training ML models. By sharing the code, we minimize the possibility of an error and reduce the time to market for the features.
Airflow also serves us as a CD tool: once the model is trained and validated, we use HTTP API to update the model in production. This was made possible by using ONNX for all the models in the inference service since they have the same interface.
Future plans
New architecture met all the requirements. By implementing it, we were able to achieve set goals within the quarter of the year, which I would consider a success.
This is what we plan to do next:
1. Trying Reinforcement Learning in the recommendations. There is a wonderful presentation by Oskar Stål from Spotify on why RL is the future of RecSys. Our architecture will allow us to store users’ cohorts and their changes in the training process while using the current cohort in the inference service and update it on the fly.
2. Service to control data skews and better monitoring overall. We have set up Spark’s metrics collection from the standalone and K8s clusters. Still, there is a lot of work left with assessing the quality of the content which goes into RecSys training, making sure that online jobs can process all the events and checking feature values against DWH as a source of truth, etc.
3. Exactly-once guarantees for the data transformations. We went to production with the at-least-once warranty provided by Spark Structured Streaming with checkpoints enabled. For a single guarantee, we plan to implement CAS (check if the batch was written in the database and apply changes in the transaction only if it was not) using BatchID provided by foreachBatch function. There are a couple of edge cases. For example, what to do if a long BatchID overflows? But all of them are solvable.
4. Migrate completely to spark-kotlin-API or Scala, adapting pySpark. It’s easier for the DS team to use pySpark API, and although it will add some operational load, we are considering adding it to the stack. In terms of Kotlin, everything works fine, and even streaming support was added, but we are still not quite sure which language will be the main in our repo.
5. Better CI/CD pipeline. There are automation scripts for everything needed to deploy a new feature group. Still, we are launching them manually since we are trying to figure out release schedules and other operation patterns. Once we figure out the process, we are going to automate everything.
6. Scaling up the number of models. At some point, the inference service won’t be able to host all the needed models for all projects and experiences. We understood this risk from the beginning and decided that when the time comes, we will implement client-side service discovery while continuing to update inference service configurations from Airflow.
Hope we gave you more insights as to why we use multiple layers in RecSys and how we deploy such a system. Lastly, we hope we gave a deeper dive on how we utilize a high-level architectural overview of the recommendation services at FUNCORP.



